在项目中你有优化过自己写过的代码吗?或者在你的项目中,你有用过哪些技巧优化你的代码,比如常用的函数防抖、节流,或者异步懒加载等。
今天一起学习一下如何利用函数缓存优化你的业务项目代码。
正文开始...
初始化一个基础项目
我们还是快速初始化一个项目
npm init -y
npm i webpack webpack-cli webpack-dev-server html-webpack-plugin --save-dev
然后新建webpack.config.js并且配置对应的内容
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
entry: {
app: './src/index.js'
},
output: {
path: path.resolve(__dirname, 'dist')
},
plugins: [
new HtmlWebpackPlugin({
template: './index.html'
})
]
};
然后新建index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>缓存函数</title>
</head>
<body>
<div id="app"></div>
</body>
</html>
对应的src/index.js
const appDom = document.getElementById('app');
console.log('hello');
appDom.innerText = 'hello webpack';
对应package.json配置执行脚本命令
{
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start:dev": "webpack serve --mode development",
"build": "webpack --config ./webpack.config.js --mode production"
}
}
执行npm run start:dev,浏览器打开http://localhost:8080 至此这个前端的简单应用已经 ok 了
至此这个前端的简单应用已经 ok 了
现在页面我需要一个需求,我要在页面中插入1000条数据
分时函数
在这之前我们使用过一个分时函数思想来优化加载数据
现在我们把这个分时函数写成一个工具函数
// utils/timerChunks.js
// 分时函数
module.exports = (sourceArr = [], callback, count = 1, wait = 200) => {
let ret,
timer = null;
const renderData = () => {
for (let i = 0; i < sourceArr.length; i++) {
// 取出数据
ret = sourceArr.shift();
callback(ret);
}
};
return () => {
if (!timer) {
// 利用定时器每隔200ms取出数据
timer = setInterval(() => {
// 如果数据取完了,就清空定时器
if (sourceArr.length === 0) {
clearInterval(timer);
ret = null;
return;
}
renderData();
}, wait);
}
};
};
由于代码中使用了es6,因此还需要配置babel-loader将es6转换成es5
npm i @babel/core @babel/cli @babel/preset-env babel-loader --save-dev
以上几个通常是babel需要安装的,修改下的webpack.config.js的module.rules
{
...
module: {
rules: [
{
test: /\.js$/,
use: [
{
loader: 'babel-loader',
options: {
presets: ['@babel/env'] // 设置预设,这个会把es6转换成es5
}
}
]
}
]
},
}
我们修改下index.js
const timerChunk = require('./utils/timerChunk');
class renderApp {
constructor(dom) {
this.dom = dom;
this.sourceArr = [];
this.appDom = new WeakMap().set(dom, dom);
}
init() {
this.createData();
// 页面创建div,然后为div内容赋值
this.createElem('hello webpack');
const curentRender = this.render();
curentRender();
}
createData() {
const arr = [],
max = 100;
for (let i = 0; i < max; i++) {
arr.push(i);
}
this.sourceArr = arr;
}
createElem(res) {
const divDom = document.createElement('div');
divDom.innerText = res;
this.appDom.get(this.dom).appendChild(divDom);
}
render() {
const { sourceArr } = this;
return timerChunk(sourceArr, (res) => {
this.createElem(res);
});
}
}
new renderApp(document.getElementById('app')).init();
ok,我们看下页面 
好像以上代码没有什么可以优化的了,并且渲染大数据做了分时函数处理。
并且我们可以测试一下代码运行的时间
console.time('start');
const timerChunk = require('./utils/timerChunk');
...
new renderApp(document.getElementById('app')).init();
console.timeEnd('start');
浏览器打印出来的大概是:start: 1.07177734375 ms
memorize 缓存函数
缓存函数其实就是当我们第二次加载的时,我们会从缓存对象中获取函数,这是一个常用的优化手段,在webpack源码中也有大量的这样的缓存函数处理
首先我们创建一个memorize工具函数
// utils/memorize.js
/**
* @desption 缓存函数
* @param {*} callback
* @returns
*/
export const memorize = (callback) => {
let cache = false;
let result = null;
return () => {
// 如果缓存标识存在,则直接返回缓存的结果
if (cache) {
return result;
} else {
// 将执行的回调函数赋值给结果
result = callback();
// 把缓存开关打开
cache = true;
// 清除传入的回调函数
callback = undefined;
return result;
}
};
};
/**
* 懒加载可执行函数
* @param {*} factory
* @returns
*/
export const lazyFunction = (factory) => {
const fac = memorize(factory);
const f = (...args) => fac()(...args);
return f;
};
我们在index.js中修改下代码
console.time('start');
const { lazyFunction } = require('./utils/memorize.js');
// const timerChunk = require('./utils/timerChunk.js')
const timerChunk = lazyFunction(() => require('./utils/timerChunk.js'));
...
new renderApp(document.getElementById('app')).init();
console.timeEnd('start');
我们看下测试结果,控制台上打印时间是start: 0.72607421875 ms
因此时间上确实是要小了不少。
那为什么memorize这个工具函数可以优化程序的性能
当我们看到这段代码是不是感觉很熟悉
export const memorize = (callback) => {
let cache = false;
let result = null;
return () => {
// 如果缓存标识存在,则直接返回缓存的结果
if (cache) {
return result;
} else {
// 将执行的回调函数赋值给结果
result = callback();
// 把缓存开关打开
cache = true;
// 清除传入的回调函数
callback = null;
return result;
}
};
};
没错,本质上就是利用闭包缓存了回调函数的结果,当第二次再次执行时,我们用了一个cache开关的标识直接返回上次缓存的结果。并且我们手动执行回调函数后,我们手动释放了callback。
并且我们使用了一个lazyFunction的方法,实际上是进一步包了一层,我们将同步引入的代码,通过可执行回调函数去处理。
所以你看到的这行代码,lazyFunction传入了一个函数
const { lazyFunction } = require('./utils/memorize.js');
// const timerChunk = require('./utils/timerChunk.js')
const timerChunk = lazyFunction(() => require('./utils/timerChunk.js'));
实际上你也可以不需要这么做,因为timerChunk.js本身就是一个函数,memorize只要保证传入的形参是一个函数就行
所以以下也是等价的,你也可以像下面这样使用
console.time('start');
const { lazyFunction, memorize } = require('./utils/memorize.js');
const timerChunk = memorize(() => require('./utils/timerChunk.js'))();
...
为此这样的一个memorize的函数就可以当成业务代码的一个通用的工具来使用了
深拷贝对象
我们再来看另外一个例子,深拷贝对象,这是一个业务代码经常有用的一个函数,我们可以用memorize来优化,在webpack源码中合并内部plugins、chunks处理啊,参考webpack.js,等等都有用这个memorize,具体我们写个简单的例子感受一下
在utils目录下新建merge.js
// utils/merge.js
const { memorize } = require('./memorize');
/**
* @desption 判断基础数据类型以及引用数据类型,替代typeof
* @param {*} val
* @returns
*/
export const isType = (val) => {
return (type) => {
return Object.prototype.toString.call(val) === `[object ${type}]`;
};
};
/**
* @desption 深拷贝一个对象
* @param {*} obj
* @param {*} targets
*/
export const mergeDeep = (obj, targets) => {
const descriptors = Object.getOwnPropertyDescriptors(targets);
// todo 针对不同的数据类型做value处理
const helpFn = (val) => {
if (isType(val)('String')) {
return val;
}
if (isType(val)('Array')) {
const ret = [];
// todo 辅助函数,递归数组内部, 这里递归可以考虑用分时函数来代替优化
const loopFn = (val) => {
val.forEach((item) => {
if (isType(item)('Object')) {
ret.push(auxiFn(item));
} else if (isType(item)('Array')) {
loopFn(item);
} else {
ret.push(item);
}
});
};
loopFn(val);
return ret;
}
if (isType(val)('Object')) {
return Object.assign(Object.create({}), val);
}
};
for (const name of Object.keys(descriptors)) {
// todo 根据name取出对象属性的每个descriptor
let descriptor = descriptors[name];
if (descriptor.get) {
const fn = descriptor.get;
Object.defineProperty(obj, name, {
configurable: false,
enumerable: true,
writable: true,
get: memorize(fn) // 参考https://github.com/webpack/webpack/blob/main/lib/index.js
});
} else {
Object.defineProperty(obj, name, {
value: helpFn(descriptor.value),
writable: true
});
}
}
return obj;
};
在index.js中引入这个merge.js,对于的source.js数据如下
// source.js
export const sourceObj = {
name: 'Maic',
public: '公众号:Web技术学苑',
children: [
{
title: 'web技术',
children: [
{
title: 'js'
},
{
title: '框架'
},
{
title: '算法'
},
{
title: 'TS'
}
]
},
{
title: '工程化',
children: [
{
title: 'webpack'
}
]
}
]
};
index.js
const { mergeDeep } = require('./utils/merge.js');
import { sourceObj } from './utils/source.js'
...
console.log(sourceObj, 'start--sourceObj')
const cacheSource = mergeDeep({}, sourceObj);
cacheSource.public = '122';
cacheSource.children[0].title = 'web技术2'
console.log(cacheSource, 'end--cacheSource')
我们可以观察出前后数据修改的变化 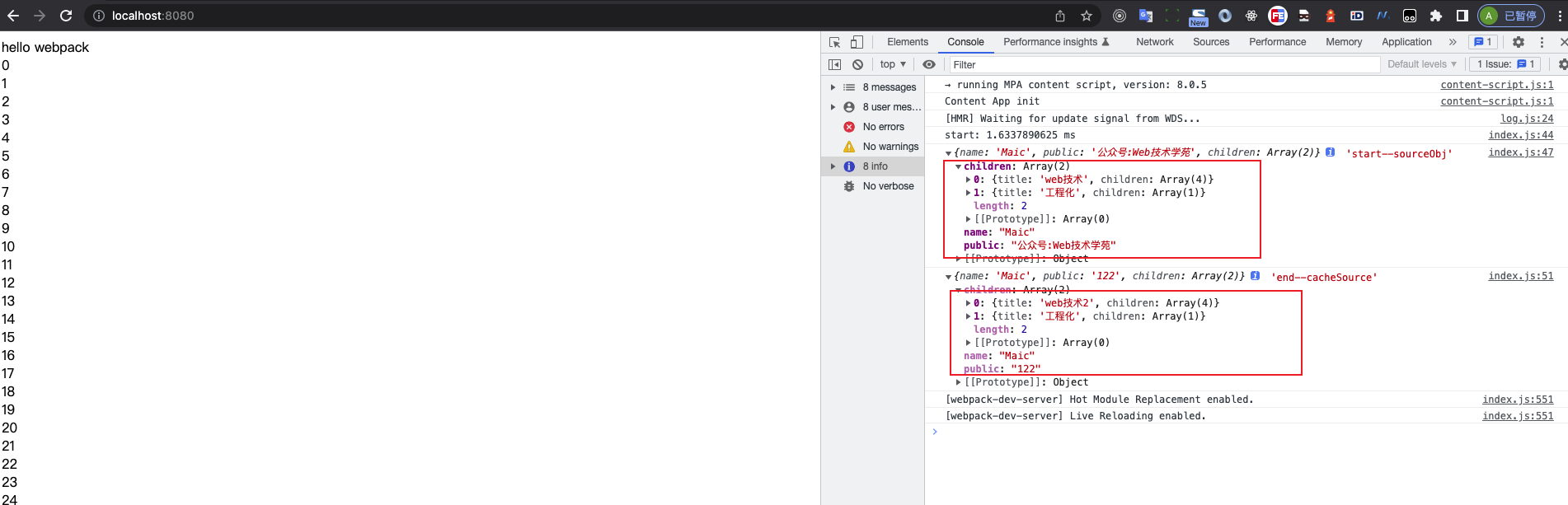
因此一个简单的深拷贝就已经完成了
总结
使用
memorize缓存函数优化代码,本质缓存函数就是巧用闭包特性,当我们首次加载回调函数时,我们会缓存其回调函数并会设置一个开关记录已经缓存,当再次使用时,我们会直接从缓存中获取函数。在业务代码中可以考虑缓存函数思想优化以往写过的代码利用
缓存函数在对象拦截中使用memorize优化,主要参考webpack源码合并多个对象写了一个简单的深拷贝,主要是
helpFn这个方法对不同数据类型的处理本文示例code-example




